皆さま、いかがお過ごしでしょうか。歌乃です。
前回、StabilityMatrix 使ってみた で AI による画像生成を試しました。
今回は、自作の追加学習モデル(LoRA)を作成して、生成される画像にオリジナル要素を付加してみたいと思います。
前提条件として
- windows 10
- git 導入済み
- python 3.10.11 導入済み
- StabilityMatrix (Stable Diffusion WebUI) 導入済み
- エラーに負けない、つよい心
となっています。例によって話の大半は戯言です。
目次
LoRA ( Low-Rank Adaptation ) は学習モデルのチューニングに関連する技術のことで、要はリソースと時間を食う学習モデルの生成プロセスを早く、低リソースでおこなっちゃうぜ、という事なのです。
LoRA自体は学習モデルを表してるわけではありませんが、追加の学習モデルの生成は LoRA が利用されるのがスタンダードになっているために、追加の学習モデルのファイルが LoRA と呼ばれています。
追加学習モデルの作り方
ありがたいことに追加学習モデル生成の手順やツールが有志の手によって作成されているのでそれを利用させてもらいます。
Kohya's GUI のインストール
Kohya's GUI は StableDiffusion用の学習スクリプトで制作者の名前から通称 Kohya版 LoRAと呼ばれているものに GUI やバッチファイルなどを追加して使いやすくしたものです。
まずは Kohya's GUI をダウンロード(git clone)します。
構築場所はどこでもOKですが、私は StabilityMatrix の実行ファイル ( StabilityMatrix.exe ) と同じ階層(ディレクトリ)に置きました。
他の場所に置く場合は path に日本語が入らない場所にしてください。
> git clone https://github.com/bmaltais/kohya_ss.git
> cd .\kohya_ss\
\kohya_ss> py -3.10 -m venv .\venv\
\kohya_ss> .\venv\Scripts\activate
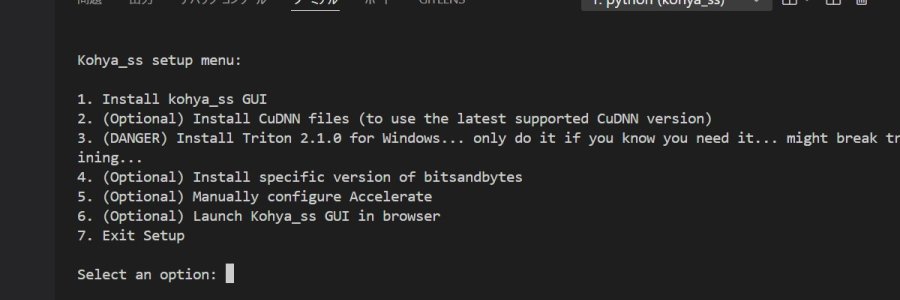
(venv)> .\setup.batsetup.bat で Kohya_ss の セットアップメニューが表示されるので

1.Install kohya_ss GUI を選択(1を入力)。
インストールが完了するまで少しかかります。
インストールが完了すると、先ほどと同じメニューが表示されるので、6 を選んで GUI を起動します。
お使いのブラウザで GUI のページが表示されます。
自動的にブラウザが開かなかった場合は、ブラウザのアドレス欄に「 http://127.0.0.1:7860」と打ち込めば GUI のページにアクセスできます。すでに7860ポートが使われていた場合は7861などになっている場合もあります。コンソールにアドレスが出ていると思うので、そちらのアドレスからアクセスしてください。
学習モデル用の画像を用意する。
AI に学習させたい画像を用意します。
20枚くらいあればいいらしいですが、それ以下でもそれ以上でも問題ありません。
今回はうちの息子の画像を16枚ほど用意しました。
画像の枚数はいくつでもかまいませんが、できれば偶数にしてください(理由は後述)。
画像のサイズはバラバラでもいけますが、できれば1:1に加工したほうがいいです。サイズは512x512、精度を上げるなら1024x1024が良いっぽいです。
画像ディレクトリを作る
学習用画像を入れる場所を用意します。先ほど構築した Kohya's GUI (Kohya_ss) の配下に「training」ディレクトリを作成します。

training ディレクトリの配下に「mylora」ディレクトリを作成します。
ディレクトリ名は好みでつけて構いません (img だけはダメ。後述)。わかりやすいものをつけましょう。
mylora ディレクトリの中に用意した画像を配置しておきます。
画像名に通番を振る
学習用の画像は処理の関係上ナンバリングが必要らしいです。hoge1、hoge2~hoge10 といった形式です。
手作業でリネームするのは大変ですが、windows の場合は簡単にできる方法があります。
画像ディレクトリ(フォルダー)内で画像を全選択 ( Ctrl + A )します。その状態でどれかのファイルを右クリックして名前を変更を選んでリネームすると、すべての画像が同じ名前になり、名前の後ろに「hoge(1).png、hoge(2).png...」といった感じで括弧付きでナンバリングが追加されます。
学習用画像の配置はこれで完了です。
画像にタグ付けを行う
やらなくてもOKらしいのですが、やっておくと学習効率と精度が上がるらしいのでやっておきます。
Kohya's GUI (Kohya_ss) の Utilitis タブに配下の、Captionning タブ配下の、WD14 Captioning タブを開きます。

次に、Image folder to caption (containing the images to caption) の項目で先ほど作った画像ディレクトリを選択します。

その下の Undesired tags には排除したいタグをカンマ区切り(最後にカンマ必要なし)で入力します。
今回は息子の画像なので 1girl, 2boys を指定しました(2boysは結果画像が二人組にならないようにするため)。
Undesired tags の下の欄は追加したいタグをカンマ区切り(最後にカンマが必要)で指定します。
指定出来たら、一番下の「Caption images」をクリックします。
ブラウザ上は変化なしですが、コンソールの方でPythonが走ってます。
タグ付けが終わるとコンソール上で「...captioning done」のメッセージが流れるので、それで完了です。
手作業でタグ付けを行う
これもやらなくていいのですが、やっておくと学習精度があがるらしいので。
WD14 Captioning タブのとなりの Manual Captioning タブを開きます。
Image folder to caption (containing the images to caption) には、前述の画像ディレクトリを指定します。

「LOAD」ボタンを押すと画像がタグと一緒に読み込まれます。
画像の横にタグが並ぶので関係のないタグからチェックを外しましょう。
AutoSave(デフォルトでON)になっていればタグを編集すればそのままセーブされます。
Next で次のページ、Prev で前ページに戻れます。
LoRAで学習(Training)させてみる
さて、本番の追加学習モデルの生成です。
Kohya's GUI (Kohya_ss) の LoRAタブを開いて、その下の Training タブを選びます。
Training タブには以下のカテゴリーがあります。
- Configuration
既存設定の読み込みや現行設定の保存などがおこなえる。 - Accelarate launch
処理を早くするための(ハードウェア的なものを含む)設定項目。 - Model
学習に使用する基本モデルなどの設定項目。 - Metadata
出力するモデルに関する情報の設定項目。 - Folders
出力先などの設定項目。 - Dataset Preparetion
学習用画像ディレクトリを生成してくれるツールなど。 - Parameters
- Basic
学習に関するパラメータの設定項目。 - Advanced
学習に関するパラメータの追加設定項目。 - Samples
学習途中のサンプル画像出力に関する項目。 - HuggingFace
HuggingFaceに関する項目。使ってないのでわかんない(´・ω・`)
- Basic
項目がいっぱいありますが、ひとつづつ片付けていきましょう。
学習用画像ディレクトリの作成
学習用画像ディレクトリ(フォルダ)には命名規則があります。めんどく間違うと大変なので、ツールに作ってもらいます。
Dataset Preparetion カテゴリを開きます。
- Instance prompt
この学習モデルを適用する際のキーワード(タグ)を指定します。短くて (3文字程度) 他のプロンプトと重複しないものが良いらしいです。今回は「mylora」にしてみました。
Instance prompt の影響がどの程度起きるかはやってみるまでわかりません。よくある英単語だと確実に精度が下がります (他の語句と認識されてしまう)。長すぎると文と解釈されてこちらも精度が下がります。
-
Class prompt
この学習モデルのカテゴリをあらわすもので、モデル(生成するモデルではなく学習に使用するモデル)が識別できるものを指定します。ここでは「1boy」にしました。 -
Training images (directory containing the training images)
用意した画像ディレクトリを指定します。今回であれば「[インストール先]/StabilityMatrix/kohya_ss/training/mylora 」になります。
-
Repeats
学習の反復回数。多すぎても少なすぎてもだめらしいです。今回は 20 にしています。 -
Destination training directory (where formatted training and regularisation folders will be placed)
自動生成してくれる学習用画像ディレクトリの出力先。今回は「[インストール先]/StabilityMatrix/kohya_ss/training 」にします。

カテゴリーの下にある「Prepare training data」ボタンをクリックします。
変化なしに見えますが、training ディレクトリの下に「 img 」ディレクトリ、その下に「 20_mylora 1boy 」ディレクトリ(prompt や 繰り返し回数で変化します)が生成されているはずです。
前述の画像ディレクトリに「img」が使えなかったのはこのためです。
学習モデルを選ぶ
Model カテゴリーを開きます。
下の「Pretrained model name or path」ドロップダウンリストに候補がいっぱいありますが、無視します( ゚Д゚)
その横のフォルダーアイコンを押して、Stable Diffusion で自分が使いたい(出力する追加学習モデルを併用したい)モデルを選びます。
モデルは [インストール先]/StabilityMatrix/Data/Models/StableDiffusion にあるので、StableDiffusionフォルダを選択します。
その後、ドロップダウンリストに、StableDiffusionフォルダ内のモデルが追加されるので、その中から選びます。
前回の記事でモデルに AnyLoRA を使用していたので [インストール先]/StabilityMatrix/Data/Models/StableDiffusion/anyloraCheckpoint_bakedvaeBlessedFp16.safetensors を選びます。
出力名を付ける
Trained Model output name
出力する自作学習モデルの名前を付けます。前述の Instance prompt で使用したもの(ここでは mylora )を使います。
画像フォルダーを指定する
Image folder (containing training images subfolders)
学習用画像ディレクトリの親ディレクトリを指定します。
今回の場合だと: [インストール先]/StabilityMatrix/kohya_ss/training/img
子フォルダーが複数ある場合でも全てのディレクトリを辿ってくれます。辿って欲しくない場合は親ではなく、子ディレクトリ(学習させたい画像の入った場所のみ)を指定してください。

出力先を指定する
Folders カテゴリにを開きます。
Output directory for trained model
できあがった学習モデルを出力するフォルダーです。Kohya's GUI (Kohya_ss) に元から用意されている Outputs フォルダーをドロップダウンから選びます。
出力したい場所が他にあるならそこを指定でもかまいません。
学習用パラメータを指定する
Parameters カテゴリーを開きます。
多分ここがこのツールの要なんでしょうが、よくわかりません( ゚Д゚)
「こう設定したら(私の環境では)望んでいた出力結果になった」というのをトライアンドエラーでやるしかないと思います。
Basic サブカテゴリーを開きます。
LoRA type
いろいろありますが、Standard を選びます。
Train batch size
学習時に画像を何枚一緒に処理するか、の項目。2 がいいらしいです。
Train batch size で 2 を指定しても用意した画像枚数が偶数でなくてはいけないという事はないみたいです。できれば偶数(Train batch size で割り切れる)の方が効率はいいみたいです。
Epoch
学習のセット回数。最終的なステップ数は 画像枚数 x 繰り返し数 x Epoch になるそうです。当然のことながらここを増やすと学習時間が伸びます。2 から始めて 4、6といった具合で最適な学習結果がでる回数を探します。
Max train epoch
最大セット回数。0 でOK。
Max train steps
最大ステップ回数。これ以上学習してほしくないという閾値を指定します。0 でOK。
Save every N epochs
指定セットごとにモデルのスナップショット(モデルの場合チェックポイント)を保存してくれます。
Caption file extension
学習に使用される画像のタグファイルの拡張子。.txt 以外を使っている人はここで指定してください。
Seed 乱数を指定するシード値。適当でいいらしいです。0 にするとエラー出たことがあるので、1234とか適当なのを入れてください。
LR Scheduler
学習率適用に関する何か。デフォルトのCosine でOK。
Optimizer
学習アルゴリズムに関する何か。ここを変えることで学習効率や精度が変わります。人それぞれなところがあってどれが正解というのはありません。求める画像のタイプや、許容できる学習時間によって変わります。
AdamW か、使ってるマシンが非力であれば AdamW8bit が基本。
Max resolution
用意した画像の最大サイズ。これを超える画像は縮小して使用されます(生成結果のクオリティに影響します)。今回は1024x1024 を指定。
Network Rank (Dimension) 学習時のニューラルネットワークの次元数に関する何か。要はどこまで細かく学習するか、の指定です。128 にしておきます。
Network Alpha
Network Rank への係数。高いと学習速度は上がるが精度が下がるようです。32 にします。
のこりのパラメータは全てデフォルトで触っていません。
学習開始
画面下の「Start training」で開始できます。
途中経過はコンソール画面の方で確認します。
エラーで止まるようなら、エラー内容を確認して、再度設定を変更してトライします。
今回は 画像枚数 16 * 繰り返し 20 = 320
320 / バッチ数 2 セット回数(Epoch) 6 = 960 ステップでした。
学習完了予想時間は 9:16:00 。結構かかります。
「Stop traning」でいったん止めて設定を変更します。
Max resolution を1024,1024から512,512に変更。
実行してみると学習完了予想時間は10分程度になりました。サンプル用なのでこのくらいで良しとします。
学習が無事終了するとコンソールに「Training has ended.」のメッセージが流れて、UI の Start training ボタンが復帰します。
自作LoRAを試してみる
できあがった学習モデルは「mylora.safetensors」という名前(Trained Model output name で指定した名前)で Outputs ディレクトリに出力されています。
このファイルを、[インストール先]\StabilityMatrix\Data\Models\Lora の中にコピーします。
学習モデルと追加モデル(LoRA)を選ぶ
Stability Matrix から Stable Diffusion WebUI を起動します。
Stable Diffusion checkpoint で anylora を選びます。適当なタグで画像が生成できることを確認します。

Generationタブの右端にある LoRA タブを開きます。
先ほど lora ディレクトリにコピーした「mylora」モデルが表示されているはずです。
Stable Diffusion checkpoint で選択した学習モデルと、Lora ディレクトリにある追加学習モデルの、バージョンやフォーマットが一致していないと Lora タブ内に表示されません。

追加学習モデル(LoRA)を選ぶと、プロンプトに「
追加する LoRA の名称(ここでは自作の mylora )その後ろの数字はどのていど mylora を適用するかという指定です。0で全く適用しない、数字が大きくなるほど、適用度(影響度)が大きくなります。
出力してみる
以下の条件で出力してみます。
prompt: 1boy, solo, upper body,looking at viewer, white background, multicolored hair, parted lips,jacket
negative: (worst quality, low quality:1.4), (jpeg artifacts:1.4),greyscale, monochrome, motion blur, emphasis lines, text, title, logo, signature,bad hands,missing fingers,extra_fingers,bad fingers,poorly drawn fingers,liquid fingers

自作LoRAを適用してみます。

まだそこまでの変化は出ません。

低年齢化してきた気配はあります(うちの子は9歳)。

ジャケットの色が変わったのは学習用画像に黄色のシャツがあった影響でしょう。

鼻のあたりにうちの子の面影がでてきました。

幼児っぽくなってますね。

目の大きさを除けばかなりうちの子の特徴が出てます。

ぱっと見で「似てる」と思うくらいには適用されてますね。
今回のモデルは0.8が閾値のようで、これ以降は完全に学習用画像(うちの子の写真)が反映されていました。
まとめ
追加学習用モデル LoRA を自作してみましたが、慣れればサクサク作れそうです。
素敵なツールを作ってくれた有志の方に感謝。
今回はイラスト系のモデルに実写を追加するというちょっとアレなサンプルになりましたが、実際には自分で描いたイラストを学習させて、そのタッチや構図を生成させるのが良いのではないかと思われます。
自分もそのつもりですしね (`・ω・´)